第一期 steam互动视频《一个人工智能的诞生》测评and学习
人工智能,深度学习,机器识别……说起来很简单,听起来很厉害,但,它们到底是什么?与其简单地观看视频,不如亲自上手操作。调整参数,改变视角,实时演示,只需要一点高中数学知识,你就能亲眼见证 —— 一个人工智能的诞生。
哈喽,这里是阿焰的第一篇正式个人博客,这期我想测评一部很有意思的steam游戏《一个人工智能的诞生》。体验这个作品是一个兼具乐趣和思考的奇妙旅程。在这个游戏中,你会从底层结构了解机器学习的方法,了解机器是如何产生智能的,最终掌握人工智能的核心思维。
那么话不多说,我们马上开始。
第一章 识别数字
万丈高楼平地起,这是一切的开始。
探索机器学习的旅程,就从一个小小的手写数字说起。当你看到一个阿拉伯数字时,自然可以不费吹灰之力知道这是哪一个数字,可是如果让一个机器来判断,它应该怎么做?我们可以让机器执行1+1,3.1415*1.4142,以及2^30等等,可是如何把一张图片摆在机器面前,告诉它“这是一个数字,你说出这是几”。听起来这很有难度,因为不同的人写下的字有不同的风格,很难让机器拿着一个范式去直接比对。

所以,我们要使用一些机器看得懂的方法,大家都知道一张图片是由一个一个像素组成的,我们常说的2k,4k等都是一张图片所含像素的规模。而对于计算机来说,处理100*100像素的图片和处理10000*10000像素的图片并无太大区别,规模化一向是计算机擅长的事。因此我们把手写数字问题简化成7*7像素的问题,就如下图所示:
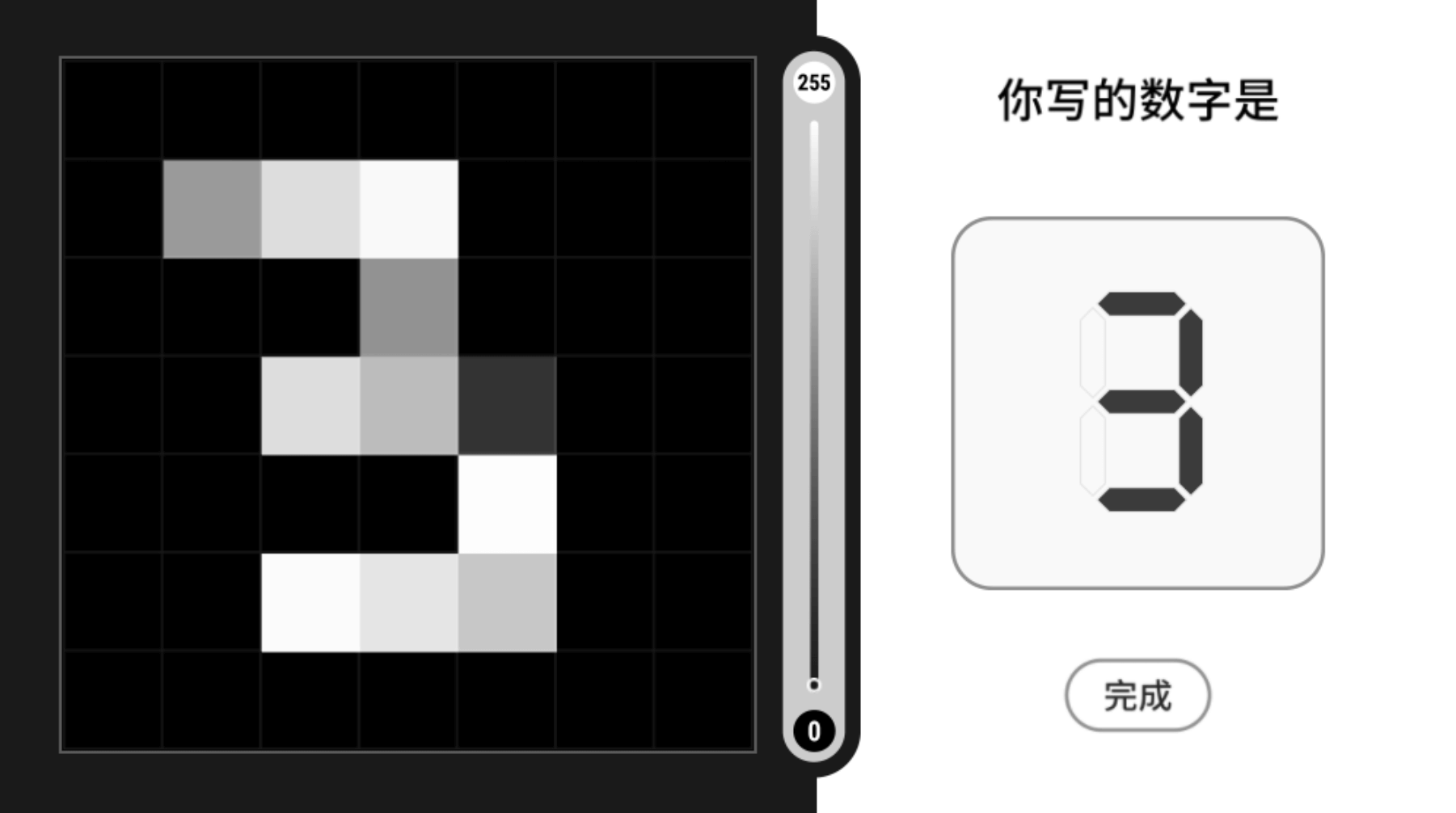
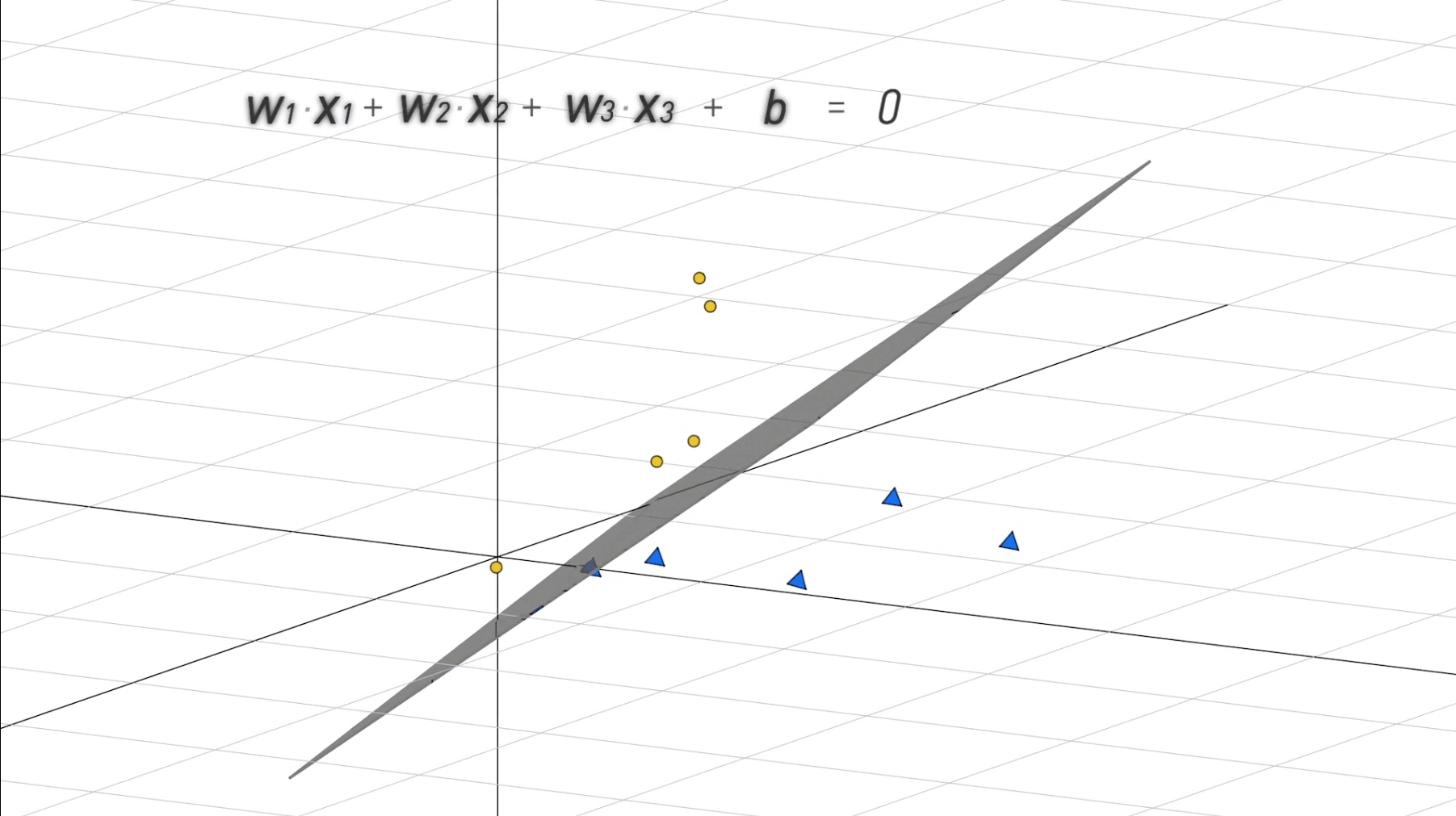
事实上,计算机能够知道的就是一张图片上的所有像素点的位置和灰度信息,通过这点,你或许已经明白了计算机识别手写数字的关键:即给每一个位置的像素添加一个权重,识别数字时只需将各位置像素的灰度与权重相乘再求和,根据最终值的大小判断手写数字类型。判断的过程在三维的表现如下图所示,一个2维平面将不同类别的测试数据区分了开来。推广至n维的结果也很简单,一个n-1维的超平面将不同测试数据区分开。而在计算机看来,不同维度的区别仅仅在变量数目的多少而已。
那么理论可行,实际又该如何操作呢?现在的关键问题就是如何让计算机为每个像素添加合适的权重,这就是机器学习的核心内容——训练模型。
模型的训练需要用到训练集,在手写数字的识别中,训练集包含了手写数字图片和对应图片的正确数字标签,即包含了题目和答案。在一开始机器拿着一个全为随机初始值的权重表依次从训练集中取出题目进行判断,然后和答案比较。如果判断对了,则不做修改,如果判断错了,就会按照一定的规则修改权重表,就如下图右上角的“权重”缩略图中展示的那样,在经过上万张训练集图片的修正后,机器的权重表会逐渐完善,判断正确率就会不断增加,到达一个很高的水平,我们此时就可以说这一次模型训练顺利完成了。
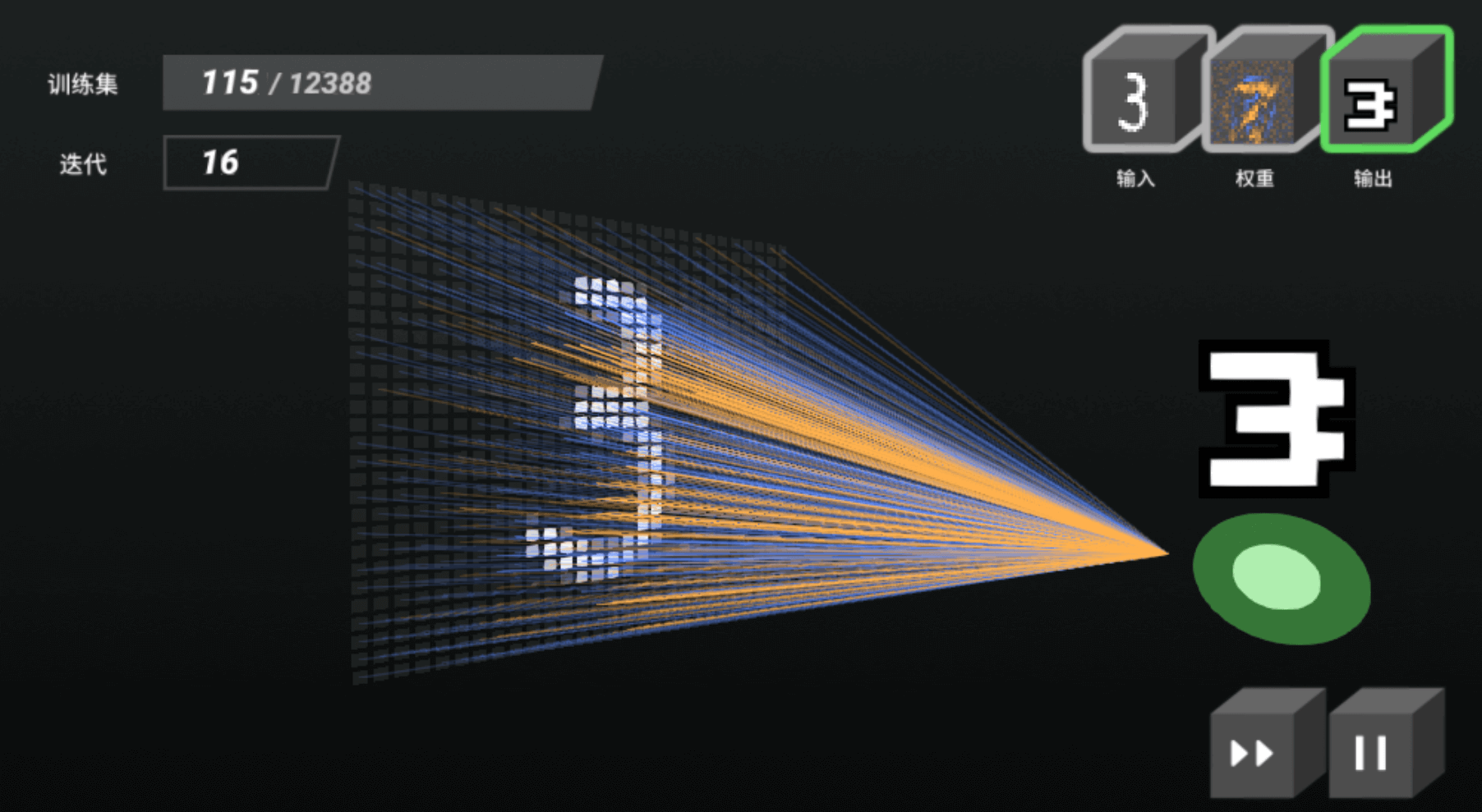
模型的训练过程看起来很简陋,甚至有些笨笨的。但是我们常说:“只要工夫深,铁杵磨成针。”计算机会进行上万次的训练,如果不满意,还能训练更多,更久,直到足够高的正确率。所以,机器学习其实是很简单的一个过程,而之前提到过的权重修正遵守的一定的规则则是核心中的核心,我们放到下一期再讲。
相逢有缘,见字如面,如果再也不能见到你,那么祝你早安 午安 还有晚安 (。•̀ᴗ-)✧